import jsonlines
from itertools import groupby
from operator import itemgetter
from ebooklib import epub, ITEM_DOCUMENT, ITEM_NAVIGATION
from bs4 import BeautifulSoup
from langchain_text_splitters import RecursiveCharacterTextSplitter
MAX_CHUNK_CHARS = 4000
def main():
epub_file = "The_Lord_of_the_Rings.epub"
jsonl_file = "The_Lord_of_the_Rings.jsonl"
print(f"Process {epub_file}...")
chunks = epub_text(epub_file)
print(f"Identified {len(chunks)} textual elements.")
for ix, chunk in enumerate(chunks):
chunk["index"] = ix
chunk["title"] = "The Lord of the Rings"
vol_book = path_to_volume_book(chunk["path"])
if vol_book:
chunk.update(vol_book)
del chunk["path"]
print(f"Writing {jsonl_file}...")
with jsonlines.open(jsonl_file, "w") as out_file:
out_file.write_all(chunks)
print("Done.")
def epub_text(epub_file):
book = epub.read_epub(epub_file)
toc = table_of_contents(book)
contents = []
for source in toc:
node = toc[source]
item = book.get_item_with_href(source)
chunks = chapter_contents(item, node)
page_chunks = coalesce_pages(chunks)
contents.extend(page_chunks)
return contents
def table_of_contents(book):
nav_items = book.get_items_of_type(ITEM_NAVIGATION)
nav_item = next(nav_items)
ncx = BeautifulSoup(nav_item.get_content(), "html.parser")
np_nodes = []
for np in ncx.find("navmap").find_all("navpoint", recursive=False):
nodes = process_navpoint(np)
np_nodes.extend(nodes)
toc = {}
for node in np_nodes:
toc[node["source"]] = node
return toc
def process_navpoint(navpoint, path=[]):
node = {
"source": navpoint.content["src"],
"label": navpoint.find("navlabel").get_text().strip(),
"path": path,
}
node.update(attr_values(navpoint.attrs))
child_path = path + [node["label"]]
nodes = [node]
for child_np in navpoint.find_all("navpoint", recursive=False):
child_nodes = process_navpoint(child_np, child_path)
nodes.extend(child_nodes)
return nodes
def attr_values(attrs):
"Book-specific interpretation of TOC attributes"
vals = {
"class": attrs["class"][0],
"id": attrs["id"],
"playorder": attrs["playorder"],
}
return vals
def chapter_contents(item, node):
chapter_chunks = []
soup = BeautifulSoup(item.get_body_content(), "html.parser")
# Iterate over every tag
page = "-"
if soup.div:
root_tag = soup.div
else:
root_tag = soup
for tag in root_tag.find_all(True, recursive=False):
if ((tag.name == "a") and
("id" in tag.attrs) and
tag["id"].startswith("page")):
page = tag["id"]
else:
chunk = {
"text": tag.get_text().strip(),
"page": page,
}
chunk.update(node)
chapter_chunks.append(chunk)
return chapter_chunks
def coalesce_pages(chunks):
"""Combine the texts of items that share the same page."""
keys = ["page"]
key_func = itemgetter(*keys)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = MAX_CHUNK_CHARS,
chunk_overlap = 0,
separators = [".\n", "\n\n", "\r\n", "\n"],
)
page_chunks = []
for page_key, page_iter in groupby(chunks, key_func):
chunk_nodes = [pi for pi in page_iter]
page_chunk_proto = chunk_nodes[0]
page_text = "\n".join(pi["text"] for pi in chunk_nodes)
page_texts = text_splitter.split_text(page_text)
for text in page_texts:
if text:
page_chunk = page_chunk_proto.copy()
page_chunk["text"] = text
page_chunks.append(page_chunk)
return page_chunks
def path_to_volume_book(path):
match path:
case []:
vol_book = None
case [volume]:
vol_book = {"volume": volume.title()}
case [volume, book]:
vol_book = {
"volume": volume.title(),
"book": book.title(),
}
return vol_book
if __name__ == "__main__":
main()New generative AI technologies can be useful for delving into detailed, world-building stories like Tolkien’s The Lord of the Rings.
First, a few examples of some questions and responses.
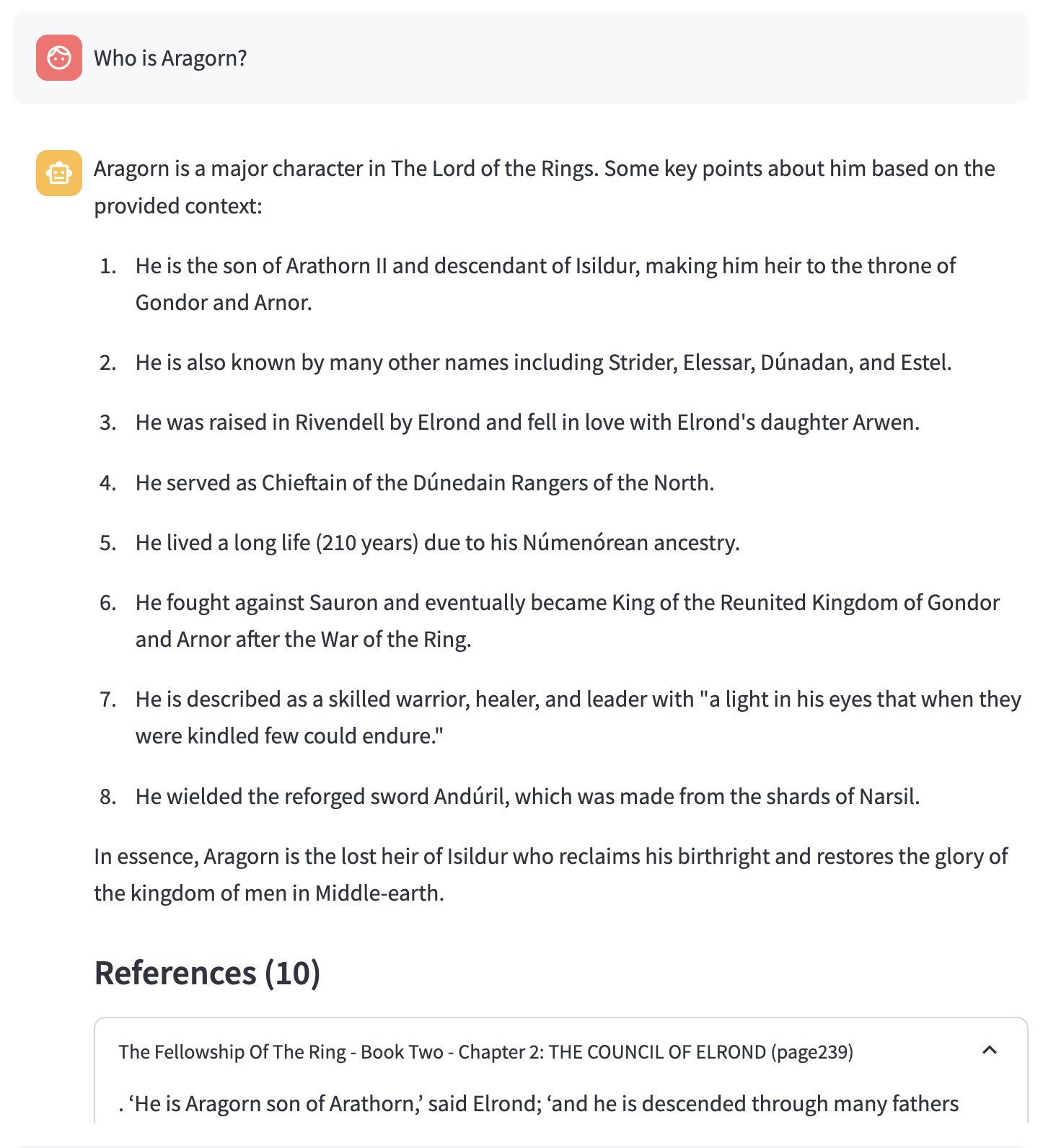
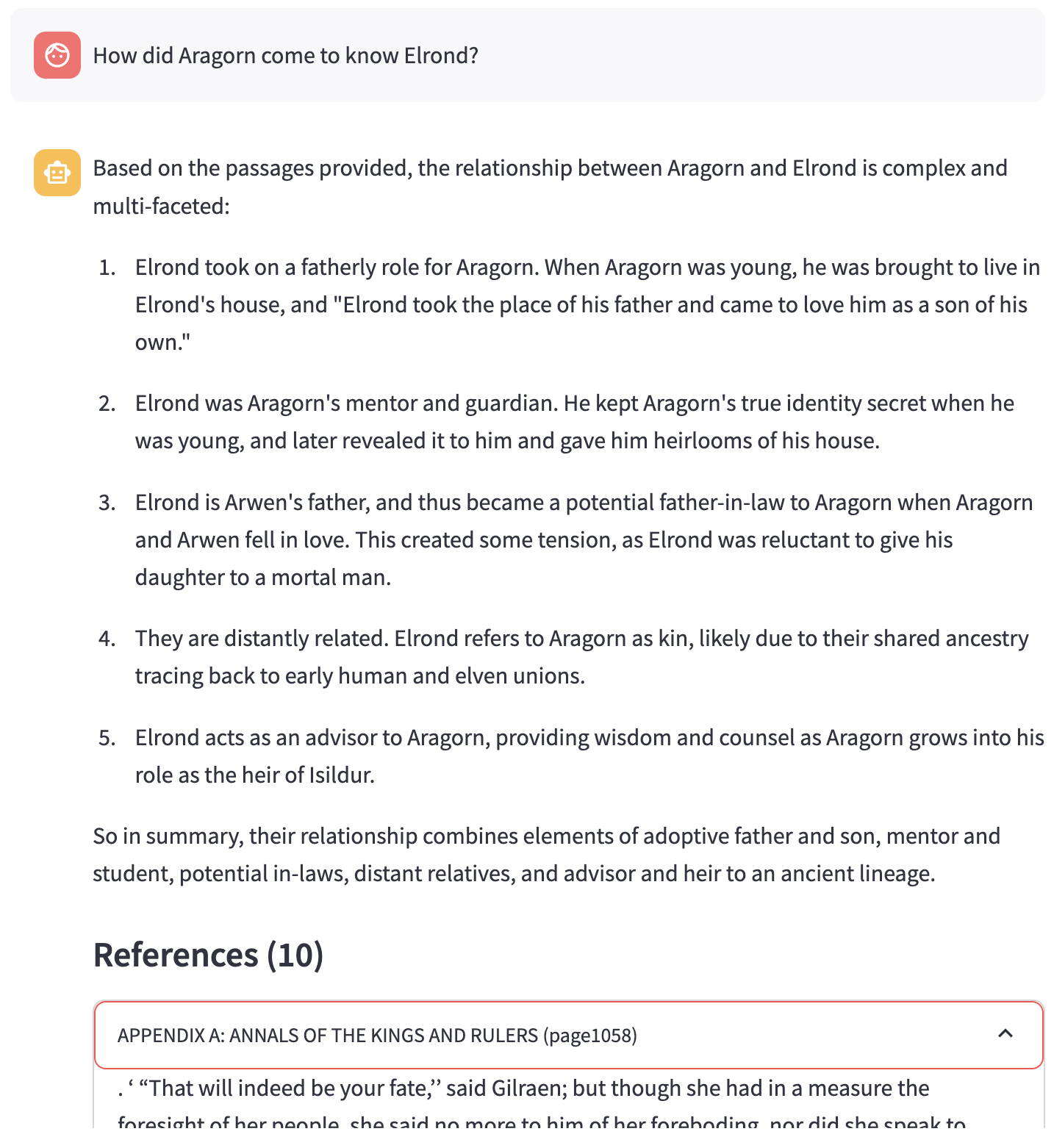
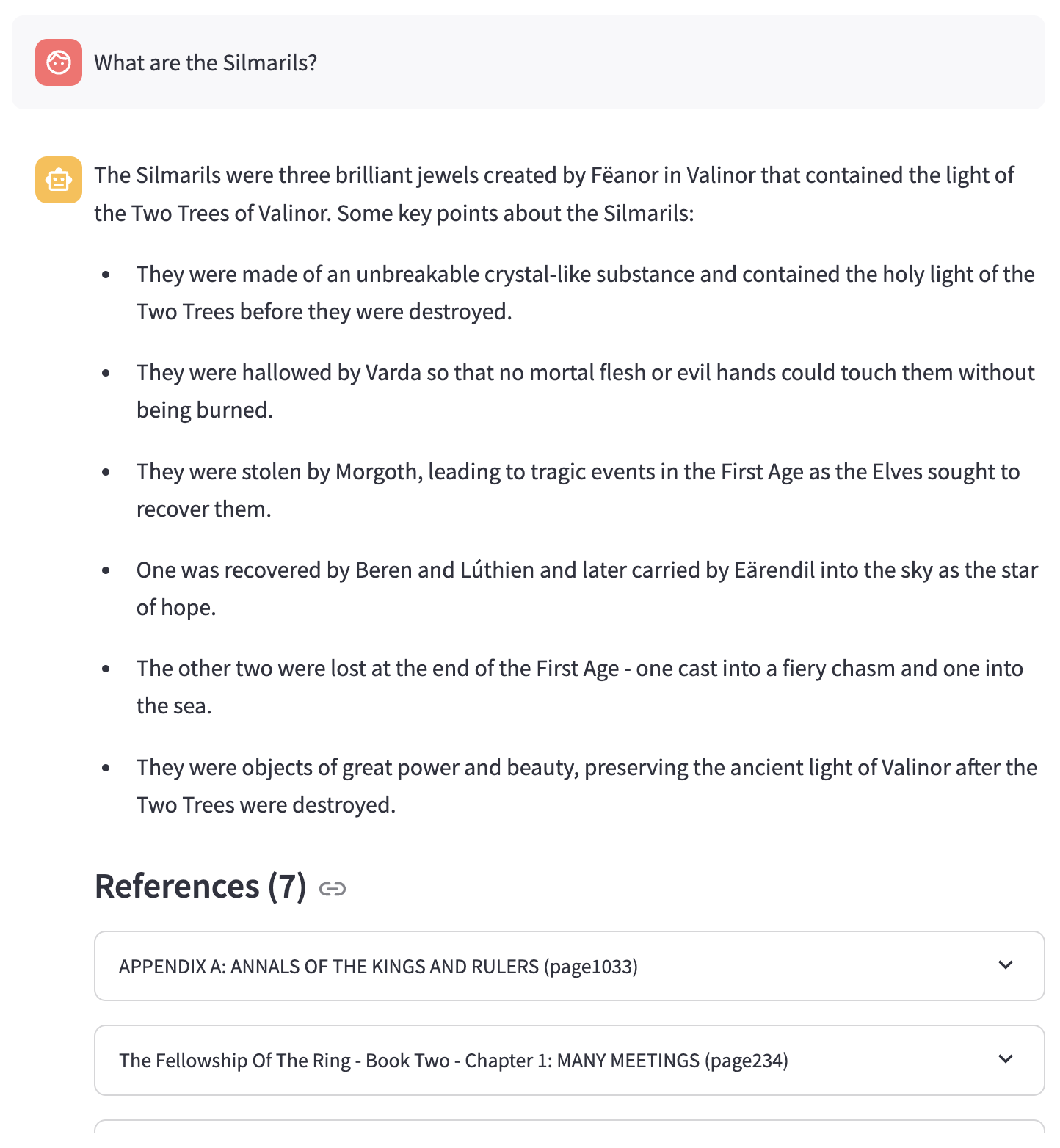
Motivation
Readers of J.R.R. Tolkien’s books and watchers of the movie adaptations develop varying levels of understanding of the complex characters, geography, and lore of Middle Earth. Some dive in, head first, poring over the driest sections of The Silmarillion and other related texts and writings, while others enjoy the stories in a more transactional context, understanding only what is needed to follow the story.
For those looking for a more in-depth experience a discussion with a well-versed Tolkien expert or reading along with others in a book club can be an avenue towards deeper understanding and enjoyment. But we don’t always have someone around that fits the bill as a discussion partner.
My son has recently started delving into The Lord of the Rings again and it gave me the idea of using Generative AI as a tool for enhancing the Tolkien experience.
This is an example of a question I asked after indexing the textual content of The Lord of the Rings books and making them available through a custom conversational retrieval chatbot using Retrieval-Augmented Generation.
Retrieval-Augmented Generation
I am a big fan of using Retrieval-Augmented Generation or RAG as a way of using Large Language Models to interact, summarize, and answer questions about a set of texts. In my work in technology and learning at Harvard Business School we have been indexing the textual elements of our active, social, case-based online business courses to create course assistant chatbots and interactive teaching elements.
The basic gist of RAG is to divide up the source text into a set of chunks that are then indexed using vector embeddings, creating a numeric vector for each textual chunk that represents (at some level) the semantics of the text. The chunks and associated This database can then be used to find a set of documents related to a query or conversation that can be passed as context to a Large Language Model (LLM) to synthesize an answer.
The advantage of using RAG compared to using an LLM like ChatGPT without RAG, is that it focuses the conversation directly on the text, minimizes bias and hallucinations, and also provides the ability to show direct references and links to the textual chunks used to create the LLM response. The current architecture of LLMs does not allow them to provide direct references to source materials.
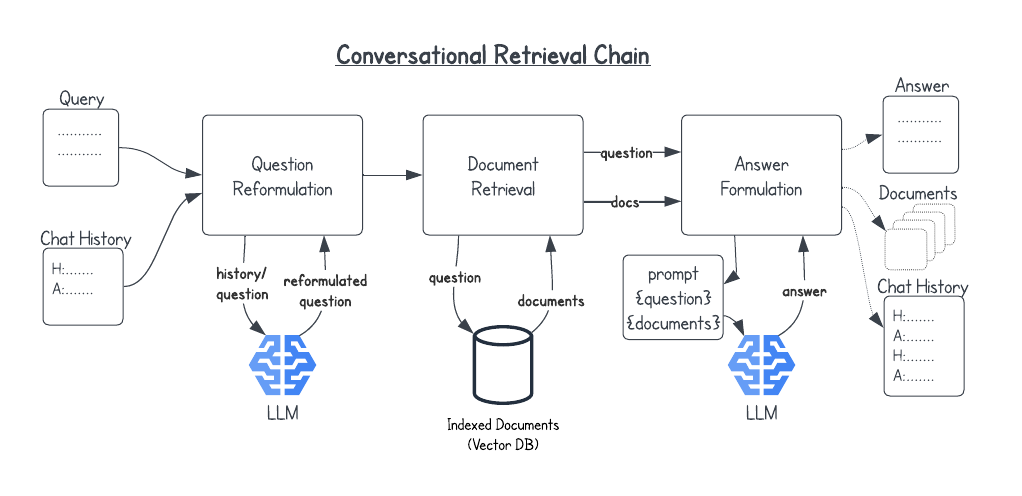
Indexing the text of The Lord of the Rings
I used an ePub version of The Lord of the Rings that included all three volumes and 6 books along with appendices. The custom chunking cusprogram (see Appendix) produces a JSONL file with each line containing a chunk of text and associated metadata like this:
{"class": "appendix",
"id": "appe-1",
"index": 991,
"label": "APPENDIX A: ANNALS OF THE KINGS AND RULERS",
"page": "page1071",
"playorder": "79",
"source": "LordoftheRings_appe-1.html",
"text": ".\n"
"After the fall of Sauron, Gimli brought south a part of the "
"Dwarf-folk of Erebor, and he became Lord of the Glittering Caves.\r\n"
" He and his people did great works in Gondor and Rohan. For "
"Minas Tirith they forged gates of mithril and steel to replace those "
"broken by the Witch-king. Legolas his friend also brought south "
"Elves out of Greenwood, and they\r\n"
" dwelt in Ithilien, and it became once again the fairest "
"country in all the westlands.\n"
"But when King Elessar gave up his life Legolas followed at last the "
"desire of his heart and sailed over Sea.",
"title": "The Lord of the Rings"}Other things to try
It would definitely make sense to add The Hobbit and The Silmarillion to the system to allow for a broader range of questions.
The use of a multi-modal embedding model would allow for indexing the maps of books as images, which might add interesting capabilities.
It would be useful to be able to do broader RAG searches to the end of creating different types of summarizations across topics, characters, or family lines.